
Short-cycle experimentation and innovation briefly working hand-in-hand as equal partners. Our recent operational risk management project with De Volksbank demonstrates just how powerful a tool this can be to quickly arrive at new insights.
Operational risk management (ORM)
De Volksbank must report annually on its most significant operational risks. Such an estimate is made up of a written description of the risk, the probability of such a risk occurring and its impact, together with the risk response. These are generally the measures taken to reduce a risk.
Set up of the experiment
The question posed by De Volksbank was: to what extent can the described risks be quantified using AI to speed up the re-evaluation process and make it more effective?
The model must be capable of attaching an appropriate probability/impact to risks described in words in terms of cause and effect. This estimate can then be compared with the department’s own estimate. If the two scores diverge widely, the risk manager can then check the risk manually.
Natural Language Processing
Pre-processing the data was an important part of this operational risk management project. This entails converting the data to make it uniform. That has to be done in such a way that inconsistencies and missing data, for example, are resolved. This represents an important aspect of our approach, because AI models often cannot deal with ‘noise’ in the data.
Modelling on the basis of text-based data is known as Natural Language Processing (NLP). Text-based data is a non-structured data source. Unlike structured data, in which each element has a set number of attributes, a written description will consist of a variable number of sentences, each with a variable number of words. Using NLP the text can be pre-processed by applying certain conventions. These include:
- Removing punctuation
- Replacing capitals with lower case letters
- Writing numbers in full
- Reducing plurals and verbs to their root.
- This process is known as lemmatization.
The next step is to look for word synonyms. This is done with word embedding which creates a type of electronic dictionary. Word embedding learns a language by reading 500 million sentences found in news reports, blogs and on fora. Words which often occur in the same context are most likely to be synonyms or have a similar meaning. This enables the system to build up a clear picture of the meaning of each word.
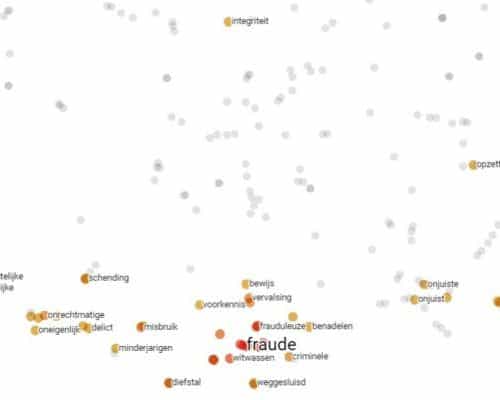
The above figure gives an impression of how word embedding works, where the distance between the words is a measure of the distance in terms of meaning. The closer to each other the words are, the more likely they are to be synonyms. In our risk descriptions we cluster these synonyms and replace them every time by the same word. In the case below, for example, the words ‘fraud’, ‘fraudulent’ and ‘money laundering’ would be considered to be the same. Risks which have the same meaning but which are described differently, therefore become equal. This makes the model more robust in dealing with certain word choices in a risk description.
Descriptive – Predictive – Prescriptive Analytics
The risk manager asks the generated model for advice: which risks should I be looking at more closely? To answer this question the model runs an analytics cycle. This cycle is made up of the following phases: descriptive analytics, predictive analytics and prescriptive analytics. Descriptive analytics is about the description of the data. What does the data tell us when direct analysis is used? Predictive analytics goes a step further and makes a prediction on the basis of the data. From here on AI becomes involved. Provided that the first two steps have been successful, prescriptive analytics can then be applied. We ask the model to advise us on the basis of the predicted results. Here we ask the model which risks need to be checked because their estimate may be either too high or too low.
During the descriptive analytics step we first look at how many risks we have per category. We estimate both the impact and frequency on a scale of one to five, so that each of the risks can be allocated to a square in a 5×5 matrix. We then look at the statistics for the words found in the risk descriptions: are there certain words (or combinations of words) which are often associated with a high impact? Or, indeed, a lower frequency? This gives us a good impression of which words in a risk description have a predictive capacity.
We use a Naive Bayes model to make predictions. This is a Machine Learning tool which is often used to sort text. A sentiment analysis is just one example. The model assumes a degree of association between certain words (or combinations of words) and categories. In our situation the categories were subdivided into probability and impact score combinations. The model is trained using historical data, following which we try to predict the probability and impact of the previous year’s risks.
The ultimate aim is to help the risk manager identify inconsistent risks. By comparing the estimate for the probability and impact made by our NLP model with the department’s own estimate, we can pick out the most divergent risks for the risk manager (prescriptive analytics). Based on the clear differences the department can set priorities and take more targeted follow up steps. This all helps to make the second line of defence more effective.
Other NLP applications for operational risk management
This project showed that AI can make a useful contribution to operational risk management. Because our model can make an objective comparison of qualitatively estimated risks, it can identify risks that deviate from this pattern and present them to the risk manager. This enabled us to provide De Volksbank with valuable information. The addition of an AI model could provide a more complete picture of the operational risks which ultimately made the assessment both more effective and more complete.
In this project NLP was applied in the area of operational risk management. However, it has many other potential applications. For the classification of transactions based on a description, for example, or to extract information automatically from company annual reports to assess the creditworthiness of a counterpart.
Would you like to know more?
Would you like to know more about NLP or what the Amsterdam Data Collective can do for you? Get in touch with Scott Bush at sbush@adc-consulting.com, or check our contact page.
What stage is your organisation in on its data-driven journey?
Discover your data maturity stage. Take our Data Maturity Assessment to find out and gain valuable insights into your organisation’s data practices.






