
BlueGen.ai is an innovative platform that tackles the challenges of data innovation and privacy preservation through synthetic data. As businesses grapple with the ever-growing need for data-driven decision-making, synthetic data has emerged as a promising solution for data sharing and privacy related challenges they run into. In this article, we will explore the potential benefits of synthetic data and discuss BlueGen.ai’s synthetic data platform, which our team had the opportunity to put to the test.
BlueGen.ai’s GDPR-Compliant Solution
BlueGen.ai is a start-up founded by tech entrepreneurs Iman Alipour and Edwin Kooistra, alongside Delft University of Technology Professor Lydia Chen. The idea originated when an insurance company approached TU Delft for a collaboration. Together they looked for a method of sharing their data without compromising privacy.
Subsequently, this led to the development of the first synthetic dataset by BlueGen.ai, allowing the insurance company to use their data without any risk of exposing privacy-sensitive information. The platform is now focused on addressing data innovation and privacy preservation challenges for organisations across industries. This includes financial services, healthcare, and the public sector.
Data innovation is a major focus for BlueGen.ai, as they help organisations to unlock the true value of their data. However, GDPR regulations can limit the use of data and restrict the full potential of data innovation. BlueGen.ai’s platform employs an AI model to learn all characteristics of a dataset. It can then generate new data points or whole copies of the dataset with the same statistical properties as the real data. For instance, the distribution and correlation of data, but without sensitive information. This is otherwise known as synthetic data.
Gartner estimates that by 2025, the use of synthetic data and transfer learning will reduce the volume of real data needed for machine learning by 70%. Furthermore, synthetic data will reduce personal customer data collection, avoiding 70% of privacy violation sanctions.
The Power of Synthetic Data
Synthetic data is a powerful tool that already has many applications and a lot of potential across various industries. Banks can use synthetic data to predict loan defaults and manage risks better. This is done by generating a synthetic data set based on various characteristics of their individual data sets. This helps create more accurate models that reduce the chances of loan defaults.
Similarly, healthcare providers can use synthetic data to prescribe personalised medicine to patients. Synthetic data is also becoming increasingly popular in open data initiatives, where it enables researchers to access data without exposing people’s personal information.
Another benefit of synthetic data is that it can be conditioned to remove biases that may exist in real data. Thereby, it both improves the quality of the data and creates more accurate and robust models. This, in turn, provides better results for businesses and helps them make more informed decisions based on accurate predictions. Overall, synthetic data can be used without including any sensitive information, which minimises the risk of exposing privacy-related data.
Testing the Potential of Synthetic Data
Our Advanced Analytics team at ADC put BlueGen.ai’s privacy enhancing technology to the test. We conducted three use cases based on situations we have run into at clients in the financial services domain. These situations include probability of default and fraud detection. The open-source dataset that we used is suited for financial risk modelling, so all use cases are set up in this context.
- Synthetic data vs. original data
We successfully verified that model development on the synthetic data resulted in a similar model and similar model performance compared to the original data. While some non-standard features needed attention, we were impressed by the overall performance. - Multiple parties collaborating on shared synthetic data
Based on the results of the first use case, we are confident that sharing synthetic data can enhance model performance. However, the challenge lies in aligning data definitions and data quality across different parties. Nonetheless, the potential benefits of this collaboration are significant. - Augmenting original datasets with synthetic data
We were able to increase model performance in terms of detecting fraudulent cases using synthetic data. Although the performance increase was similar to the conventional method of random oversampling for the specific use case and dataset we used, we believe there is potential for further improvement through exploring conditional modeling.
Overall, our experience with BlueGen.ai’s technology demonstrated the immense potential for synthetic data to improve data-driven decision-making. The technology is very easy to use, preserved privacy throughout the process, and was easily implemented in the use cases.
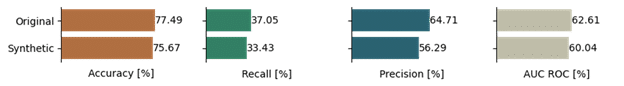
Partnering with ADC for Data Innovation
Many companies, particularly in healthcare, banking, insurance, and the private sector work with important data to make strategic decisions. However, the potential of data needs to be unlocked while respecting GDPR privacy and other legal reasons that make it challenging for companies to access, share, and use data effectively.
Privacy enhancing technology allows us to quickly see what the data looks like without accessing the sensitive information. Consequently, we can safely facilitate innovation and enable our clients to unlock the full potential of their data.
At ADC, we understand the potential requirements and challenges that come with data access, and we have the expertise to bridge the gap between the problem and solution with an innovative mindset. By working with us, organisations can provide safe access to their data and improve their overall operations.
Let's shape the future
Would you like to know more about synthetic data or our partnership with BlueGen.ai? Get in touch with Joost Veenkamp via jveenkamp@adc-consulting.com or check our contact page.

What stage is your organisation in on its data-driven journey?
Discover your data maturity stage. Take our Data Maturity Assessment to find out and gain valuable insights into your organisation’s data practices.






